





































Have you ever looked at your phone with pictures of beaches appearing in a few seconds after typing “beaches” into the picture search on your phone? If that has happened to you, I am sure you were shocked by how many beaches and waves you took pictures of that could be instantly shown to you based on the tens of thousands of other pictures taken of those beaches.

That seems like a little bit of magic when all you did was simply enter “beaches”, right? That also isn’t an example of magic; instead, it is a highly advanced process that lets your cell phone recognize what a beach looks like from the photos it takes.
A machine (that doesn’t know anything about memories or locations) identifies a complex object (such as a beach) in a photo by breaking the image down into its most basic elements: specifically, it breaks the entire image into millions of tiny, individual colored blocks called pixels. A beautiful photo of a sunset is just a large grid of numbers that tell you the exact color of each dot.
The transition from recognizing a number on a grid to determining what a picture depicts is fundamental to how visual recognition functions. Amazingly, the function itself is almost indistinguishable from the way humans think when they are trying to understand how something operates.
This is because the system is taught, similar to the way children are taught, by showing it hundreds or thousands of pictures of different cars and objects that have been hand-labeled (manually) by us. As the system views all of these examples, it begins to develop common characteristics—four wheels, windows, certain geometric shapes—that define an object. In essence, it is the process of developing the computer’s ability to recognize similarities among patterns in an object, allowing AI to correctly recognize pictures.
This tutorial will walk you through, step by step, how the AI-based Watch Image Recognition System can accurately recognize objects using its pattern-recognition capabilities, and how this pattern recognition is used in the applications you likely use every day. The method by which AI recognizes images is referred to as Deep Learning Image Recognition.
This reference manual will provide an overview of how image recognition creates a numerical representation of a pixelated grid of pixels and how it identifies basic features in an image (edges, texture, corners) by utilizing layered neural networks that have been trained on large amounts of labeled data to identify patterns. Image recognition models are created using machine learning concepts that rely on probability-based prediction to identify, detect, and classify objects in images and are used in many applications, including Medical Imaging, Driver Assistance Systems, and Retail.
In addition, this reference manual will examine some of the more common ways that the image recognition process may fail or introduce bias into results — i.e., why the quality and diversity of the training data determines how well the model will perform — and how this can cause issues such as identifying muffins or chihuahua’s incorrectly. Once you understand the end-to-end processing pipeline for an image recognition system, you will have a clearer sense of what is possible and what is limited in how image recognition technology operates.
How Image Recognition Works?
Image recognition is a multi-step process that includes identifying, detecting, and/or recognizing objects, scenes, and/or patterns in images. The core of image recognition is based on powerful computer algorithms and artificial intelligence (AI) technologies that analyze visual data. The first step in the image recognition process is the input of the image into the recognition system, where it is broken down into its constituent parts, and features are extracted from each component. Features can include one or more of color, shape, texture, etc., that assist the recognition system in identifying the object(s) within the image.
The second step in the image recognition process is extracting features from the image, which are then compared against a large database of known images and patterns to find a match. The comparison of the feature(s) typically uses machine learning (the system has been trained on numerous image databases, so it knows what to look for). Once the system locates an image/pattern that matches the one you wish to identify, it will label the image with labels and contextual information.
In addition to the accuracy of image recognition, both deep learning and neural networks can greatly enhance the accuracy of image recognition through the use of “learning” from previous experiences. As both deep learning and neural networks learn from additional experience/data, they will increase their ability to recognize objects. This is why image recognition has been utilized in many applications, including social media’s auto-tagging and advanced security systems that use facial features to recognize individuals in real time.
The Image Recognition Processing Pipeline

Example: Modern deep learning models analyze millions of pixels and patterns before predicting an object.
Source: Stanford Computer Vision Lab
https://vision.stanford.edu
Machine Learning Image Recognition
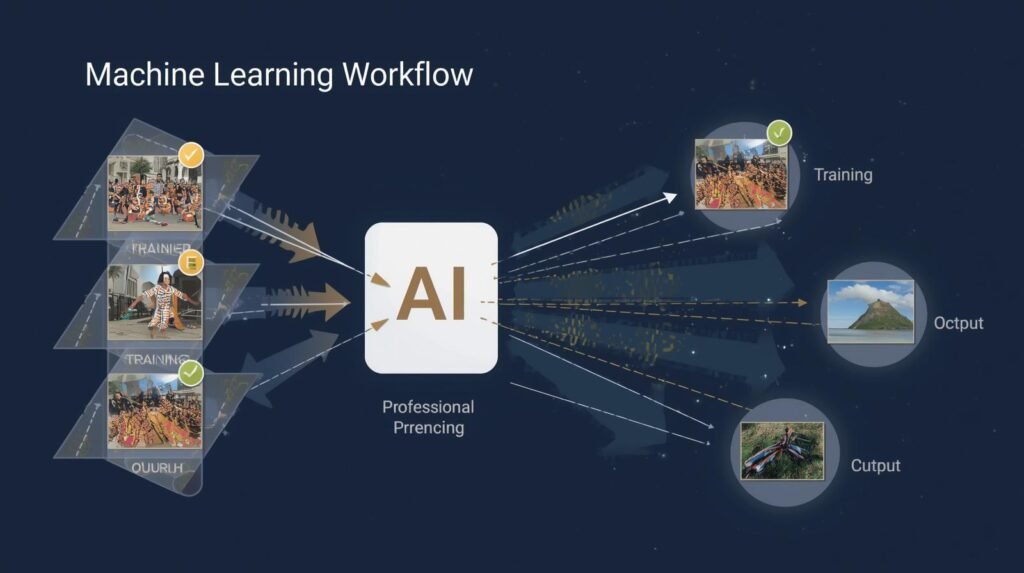
Machine Learning Image Recognition is one of the many subsets of Artificial Intelligence (AI) that allows computer systems to visually recognize and interpret items in their environment using various algorithms and techniques. Machine Learning Image Recognition can be used for more than just identifying patterns, faces, and objects in images; it is used across multiple industries to automate processes, such as automotive and healthcare, while social media platforms and smartphone applications also use it to enhance user experience.
The initial step in Machine Learning Image Recognition is providing the model with a large database of labeled images to learn from. The model learns as it examines additional images and continues to improve at identifying similarities between categories/classes of objects (e.g., dogs vs. cats, brand logos). Ultimately, the goal of machine learning for image recognition is to enable computers to accurately predict whether an object is familiar or unfamiliar from previously unseen images. This increases the potential for greater use and functionality of machine-learning image recognition across all types of applications.
How Machine Learning Trains Image Recognition Models

Example: Image recognition models such as ImageNet were trained on over 14 million labeled images.
Source: ImageNet Dataset project
https://www.image-net.org
Deep Learning Image Recognition

Deep Learning Image Recognition is a branch of Artificial Intelligence (AI) that uses algorithms to train systems to view and interpret images much as we do. Deep Learning Image Recognition depends heavily upon the use of a very large number of data sets (i.e., images) and utilizes advanced algorithmic methods specifically designed for handling image-based data inputs, so that AI systems may have the capability to “see,” identify and analyze the object(s), face(s), pattern(s), and characteristics of still images and/or video.
Training occurs when a large amount of labeled image data is provided to a neural network, a simulated computer system based on the structural organization of the human brain. The neural network becomes capable of identifying many of the characteristics and features in the images used during training, as well as improving its ability to identify and classify images it has never previously viewed.
As deep learning image recognition continues to develop, it is expected to have a significant impact on virtually all areas of society. Its use is already evident in the health care industry, where medical imaging is used to aid in disease diagnosis by analyzing images such as X-rays and MRIs. Businesses are utilizing deep learning image recognition to track consumer behavior and provide each individual with a customized shopping experience.
Additionally, deep learning image recognition is being utilized to enhance the capabilities of self-driving cars. To operate safely, self-driving cars must be able to recognize road signs, pedestrians, and other vehicles. Thus, image recognition is developing new ways to interface with computers and paving the way for the next generation of artificial intelligence.
Image Classification vs Object Detection

Example: Autonomous vehicles use object detection to simultaneously identify pedestrians, vehicles, and traffic signs.
Source: NVIDIA Computer Vision Guide
https://developer.nvidia.com/computer-vision
How Does an AI See an Image? It Starts with a Million Tiny Dots
Quickly looking at an image causes your mind to immediately identify people, locations, and objects. On the other hand, Artificial Intelligence views an image quite differently from humans. Instead of recognizing one image (as we see it), a computer recognizes a massive mosaic made up of millions of very small individual dots of color, which is essentially the start of a method used to convert our visual perception of images into numerical representations; therefore, this will demonstrate how image recognition functions.
Take a close look at the apple above. You can see each of the many little colored squares making up the form of the apple. These are called pixels, the smallest units of a digital image. Each photograph you take with your smartphone and each image on the internet is really a grid of the previously mentioned tiny, colored squares arranged so that, when you look at them, you perceive a complete picture.
The computer then converts the image into an array of data (pixels), where each pixel has a value that specifies both its color and light intensity. This creates an enormous amount of data, which serves as the basis for the AI to identify which objects are present in the photo. The AI does this by identifying patterns in the data, since it is blind to visual cues and can’t “see” anything. This is essentially the start of the AI’s actual processing. It takes all the data from the photograph and finds patterns.
This process is similar to using a large spreadsheet to find items with specific characteristics, such as a certain number of sides or a certain color.
What Are the First Clues an AI Looks For? Finding Simple Patterns
The AI needs to do another job after converting the image into a number grid: turn it into something useful. The AI does this by acting as a detective. The AI doesn’t look at the whole picture; it looks for the smallest pieces of evidence or signs in the data.
During the first pass through the number grid, the AI first looks for simple patterns in the data. Rather than try to find the “face” or “tree”, etc., the AI simply tries to see where there are sudden changes in the numbers represented by each pixel. If the AI sees these sudden changes, it sees an edge. Where two or more edges intersect, the AI will have found a corner. When the AI finds a bunch of pixels all representing the same color, it has found a color patch. Most artificial intelligence pattern recognition is used to recognize the simplest geometric shapes possible in an image.
The first important step in deriving foundation units from unprocessed raw pixel data is feature extraction. Feature extraction can be viewed as AI creating a “simplified” version of the image’s “map”: rather than millions of pixels, the AI now has a map of the lines, curves, and textures that define the image’s salient characteristics. What is actually feature extraction in images? Feature Extraction is nothing more than taking raw data and translating it into usable data – a single, simple clue at a time. In fact, Feature Extraction is one of the very early and most effective methods in image recognition.
Lines and Corners will produce a cat. Like each individual LEGO brick, these characteristics are much like individual pieces of a puzzle. While each piece is vital in its own right, instructions are needed for assembling the individual pieces so that the simple pieces can be identified as a whisker, an ear, or a tail. Therefore, the AI will need to go to school to learn how to use the technique called a massive set of digital flashcards to assemble the individual LEGO bricks.
How Computer Vision Works?

Computer Vision is a subset of Artificial Intelligence (AI) and is very interesting because it concerns how computers can view and interpret the visual environment in which we live. Developing algorithms and models that enable computers to identify objects, people, and other elements in still images or video is the foundation of Computer Vision. Typically, acquiring visual data with a camera or sensor is the first step in developing a Computer Vision system. Following this acquisition, the visual data is processed to clean the image, remove unwanted noise, and create a high-quality, ready-to-analyze dataset.
#What Is Computer Vision: How AI Smartly Sees the World
The next most common step in creating a Computer Vision system, after processing visual data, is feature extraction. Feature Extraction is the process by which a computer identifies significant elements in images so they can be identified later. In Computer Vision, these features include edges, shapes, and textures, and are used to help the computer understand and identify objects, scenes, etc., in images.
Deep Learning techniques are also commonly used for Feature Extraction; deep learning uses artificial neural networks that can be trained on a large number of labeled images, e.g., “animal”, “car”, etc. Once trained, the network can accurately predict the location(s) and existence of objects in new images it has never seen before.
Computer Vision systems will use the predicted information for a variety of applications. For instance, Facial Recognition Technology (FRT) uses computer vision to identify and authenticate people based on the physical attributes of their faces. Additionally, computer vision assists Autonomous Vehicles; these vehicles can recognize and distinguish traffic signs, pedestrians, and other vehicles while operating, enabling them to comply with the laws of the road.
Another area where computer vision has been used is in medical imaging. Computer Vision will assist physicians in diagnosing diseases by examining and evaluating X-rays, MRIs, CT scans, and other medical images. Lastly, Quality Control in Industrial Automation is yet another area where computer vision has been utilized. Companies can track and assess production at an earlier stage to help minimize waste and errors through monitoring items as they move along an assembly line.
In general, computer vision combines today’s technology and advanced algorithms to narrow the gap between how humans understand and interpret visual information and how computers and machines process and analyze it.
Real-World Applications of Image Recognition

Example: Google Photos uses image recognition to automatically organize photos based on objects, locations, and faces.
Source: Google AI Research
https://ai.google
How Do You Teach a Computer What a ‘Dog’ Is? The Digital Flashcard Method
To learn what dogs are, a computer uses a large database of digital flashcards. To teach a computer to recognize a dog, you don’t need to write an extremely complicated algorithm telling the computer to search for fur and wagging tails. Instead, you will display thousands of pictures of dogs (as well as many other pictures) to a computer. Each picture must be labeled by humans (e.g., “dog,” “car,” “tree”). Labeling these pictures with the appropriate words is called data collection and labeling; it is the first step in training an image recognition model.
The AI model has access to the image library once the images have been collected and labeled, at which time it can do its homework. Its work is highly detailed; the system compares each image labeled “dog” against the shapes, lines, curves, and textures it had previously defined. As the system reviews these images, it finds patterns and relationships. In particular, it finds that images commonly labeled as “dogs” tend to have a combination of furry textures, an upside-down triangle above each ear, and a circular black area for the nose.
The system has no way to think of “dog” in the same way humans do. Instead, the system uses a statistical formula based on visual characteristics and applies it simultaneously, allowing it to accurately conclude that an image is most likely a “dog”.
At the end of this process, digital brain “models” are created to accomplish a specific task (for example, to identify images or objects). The reason is that the digital brains were able to compile a massive library of knowledge from the tremendous amount of information used during training. This knowledge is in the form of statistical relationships between each feature and its corresponding label. In essence, after a large library of data is processed and the commonalities of the data are identified, a large body of information is reduced to a single tool that performs one function – the model.
Once you have created a model, you have completed the study phase, and the AI model can now graduate from flash card study to testing. Now the AI model will be shown a brand new photo it has never seen before and asked to predict what type of object it is. Therefore, how does the model use all the clues provided by the new picture to make a confident prediction (such as, ” I am 94% sure that is a dog”)? The model accomplishes this by creating a layered analysis of all of its knowledge – much like a team of experts working together to solve a puzzle – and the layered analysis is very important to how image recognition works.
How Does the AI Make a Final Guess? Thinking in Layers
The model does not just take a look at the new picture and instantly figure out what is in it. Instead, it uses several layers of processing to reach a conclusion through a multi-step method, much like a game of 20 Questions, where each answer helps determine the next question (s) to ask. In addition, these types of models are often referred to as Neural Networks; however, they can also be viewed as nothing more than a Production Line or Assembly Line of Experts, with each expert contributing their piece of information to create the final product developed by all the previous experts.
It is because of this layered processing that an AI can go from identifying a straight line to identifying a complex item. Think of this as a new image being sent to a computer to find out if the new image shows a human face. Each layer becomes progressively more difficult to solve as the data moves through each layer.
- Level 1 (Basic Elements): At this level, the experts can only detect the simplest forms in images. Once they’ve found them, they report back to Level 2 with descriptions such as “I detected a strong vertical line,” “I detected a slight curve,” and “I detected a small, dark circle.”
- Level 2 (Pattern Building): The next level uses information from Level 1 to find patterns in images. They might say, “The ovals created by the curved lines could mean an egg” or “The two dark circles are probably eyes.”
- Level 3 (Final Decision): The final level receives all the reports and makes its own decisions based on what it sees. Using a description of an oval, two eye-shaped circles, and a nose-shaped element, the managers believe the image is a face and are right 95% of the time.
The last answer wasn’t simply a yes/no answer – the last answer was actually a confidence measure – a probability. The model doesn’t know for sure whether a new image will look like the images used to train it; instead, it estimates how likely it is that a new image will resemble those images. That’s why technology is prone to error. For example, when a photo-tagging app identifies a Cabbage Patch Kid Doll as a real person, the doll looks similar to the ‘face’ model’s feature representations, the model guesses very accurately (with high confidence) even though it is wrong.
All of these processes happen within less than a second – from pixel processing to generating the final probability. The ability for an AI to see and analyze a world it has never seen before comes from the layering and statistical processing. However, identifying a single object is merely the first step in a much larger task. Now, the next question is: how does the AI perceive the entire scene? Is the AI capable of recognizing a photo as simply a ‘beach photo’, or is the AI capable of determining if there is a boat present on the beach? A capability such as this represents a significant advancement in the field of artificial intelligence.
Global Image Recognition Market Growth

Source: Fortune Business Insights – Image Recognition Market
https://www.fortunebusinessinsights.com/image-recognition-market-103265
Object Detection in Images

Object detection is one of many areas of computer vision. It seeks to identify and locate every object present in an image. Machine Learning and AI techniques are used to train machines to find and identify many types of objects (e.g., people, dogs, cars) and the most common ones. A number of possible applications require the ability to rapidly and correctly recognize and classify objects in images; for example, video-based security surveillance systems, autonomous vehicle systems for transportation, and tag-and-categorize capabilities on social media platforms.
#Object Detection vs Image Classification – The Ultimate Easy Guide
CNNs are the primary method for object detection, as they are highly adept at extracting features from images. Once a CNN has learned to extract features from the thousands of images in its training dataset, it can take in new images, detect objects in them, and draw a bounding box around each detected object. As a result of advancements in the field of Object Detection, more efficient algorithms are now available.
The efficiency of these new algorithms allows for real-time object detection. Real-time object detection is critical to enabling a system to process a live video feed and react to changes in its environment. Object Detection continues to evolve through technological advances and ongoing innovation in the field of research.
Is It a ‘Beach Photo’ or Is There a ‘Boat on the Beach’? A Crucial AI Distinction
The distinction you’re making between scenes and objects in those scenes relates directly to two different, but complementary, categories of capability for artificial intelligence. The first category is image classification; it provides a single label for the entire image. Your smartphone can categorize your photographs in your photo album by titles such as “Sunset,” “Food,” or “Pet.” Classification provides a single high-level category or theme for each individual photograph. An Artificial Intelligence will take a complete view of the picture and then draw conclusions from what it sees.
However, using a single title may be insufficient. It is then that the more advanced ability to identify objects in images becomes applicable. Image object detection does not ask merely, “What is this a picture of?” Instead, object detection in images asks, “What specific objects are in this picture? And where are the specific objects?” Object detection in images allows for greater detail in searching for all of the objects in the images and also allows for the placement of an invisible box around each object identified in the images, with precision as to where each object was located (that is, a person is here, a car is here, a dog is there).
Classification is about labeling a book; Detection is about making a Table of Contents for the same book. Identifying what is happening in a scene and who is in it is a big initial step in the process. It is crucial to learn how to develop Classification and Detection models, as it will lead to many other technologies that will help us interact with the world beyond just our Smartphones. Therefore, learning how images are recognized is needed at multiple levels.
Social media sites frequently provide you with the option to tag a friend in a photo using facial detection to isolate their face. In addition, fun camera applications add virtual glasses to your head as you take a picture, using real-time facial detection to determine the exact positions of your face, eyes, and nose.
In essence, the difference between Classification and Detection is that Classification is giving a title to a book, and Detection is creating a table of contents for the same book. The large leap from determining a scene’s theme to identifying who is in it is one of the first steps toward accomplishing this. Understanding how to create Classification and Detection models has allowed many new technologies that are changing the way we interact with the world, well beyond our smartphones. Therefore, understanding how Image Recognition functions is required at multiple levels.
Where You See AI Vision Working in the Real World (It’s Not Just Your Photos)
The ability to recognize individual images is being used to improve efficiency, reduce costs, and enhance lives through a variety of applications. The ability to recognize the faces of friends and family, once exclusive to your smartphone, is now being utilized across many industries.
An example of how image recognition is used in the healthcare industry is in radiology, where radiologists view thousands of medical scans each year. An artificial intelligence (AI) system can be trained on millions of medical scans to analyze X-rays or MRIs for abnormalities that may indicate an emerging disease. The AI is not replacing doctors; it is serving as a second set of eyes to help doctors identify potential issues faster and more accurately by leveraging deep learning for image recognition.
The “see and react” method of pedestrian detection in vehicles which will automatically stop when a pedestrian enters a roadway uses the same basic principles as a camera system designed to assist a vehicle driver from drifting out of the center of the road through the use of continuous surveillance of all items around the vehicle, (surrounding object, lane lines, traffic signs), to quickly make decisions about what needs to be done to maintain safety. This technology is also currently being used in retail to allow consumers to shop without cash and to enable retailers to charge customers using cameras that identify items placed in their shopping baskets.
There is one major drawback to using advanced technologies for life-or-death decisions: the rate at which they fail to produce correct results. Advanced technology has flaws regardless of how well developed it is, and an area of continuing concern in the decision-making process with AI technology remains: What happens if the computer misidentifies the image? Just like even the most advanced AI may occasionally have errors in its decision-making process, and in doing so, cause confusion — and sometimes severe consequences — due to the AI’s inability to accurately interpret images.
Why Your Phone Thinks a Muffin Is a Chihuahua: When Good AI Goes Bad
What happens when these systems fail? Sometimes, they just generate something that doesn’t make any sense at all. I’m sure most of us have seen the Internet meme where a picture of a blueberry muffin looks like a Chihuahua’s face — personally, I think I could easily tell them apart. But to an AI trained to identify small, round objects with dark spots, the basic features of both pictures are quite similar. The reason for this isn’t because the AI is confused, which may happen to humans, but rather that the AI is doing its best based on the limited amount of visual data that it had been trained on.

Most often, these errors stem from how the training data was used in developing the artificial intelligence. In particular, which educational (or training) data were used for the model’s development? As the model’s ability to accurately identify images is directly tied to both the quality and variety of flashcards it was provided to learn from, if you have only shown the model pictures of cars on sunny days, it will probably not be able to recognize a car covered with snow. It’s not about making the image recognition model smarter; it’s about providing the model with richer, more varied information to learn from.
When human bias exists in data, it also introduces challenges for facial recognition technology. A system trained on photos of mainly lighter-skinned individuals will perform poorly at recognizing people with dark skin. The system did not intentionally exclude darker-skinned individuals; however, it will also not do an adequate job of recognizing them because of its own lack of experience (‘training’) and bias (the same type of bias present in the data provided to it) regarding how the world is represented.
This failure illustrates the basic truth of the system: it does not see a “face” or a “muffin”, it sees only a grid of numbers and uses patterns it has learned from past experiences to statistically infer what something probably looks like. Understanding this fundamental difference provides you with a new level of clarity about how machines view and interpret our world.
You Now Have a New Superpower: Seeing the World Like an AI
Prior to understanding how computerized technology (like a smartphone) works, what once seemed like nothing short of pure digital magic can now be understood and visualized. In the past, finding all of the pictures labeled “beach” on your phone was a big deal. However, at the time, people did not know how it worked. As such, today, you have an understanding of the step-by-step logical process of how a bank’s application can quickly take the billions of pixels in each image (made up of a mosaic of colors), and create line patterns and textures that ultimately lead to one final conclusion or guess: “That is a beach.”
As you have learned, there are millions of “digital flashcards” that enable image-recognition learning. Each “flashcard” comprises digital “expert” layers that work together to take the patterns developed from the images and provide a final, conclusive answer, i.e., “That is a beach.” Understanding how image recognition learning occurs helps you appreciate the breadth of disciplines involved in artificial intelligence (AI).
With this new understanding of how technology works, when you use your banking app to deposit a check or unlock your phone with facial recognition, you will see the same process at work. Prior to understanding how the technology works, what seemed like “magic” is now understood as a method.













{kind=link}
Comments 1