
















Artificial Intelligence has moved beyond being merely an imaginative idea for future applications to shaping how we live our daily lives through our jobs, creative processes, and problem-solving. Many organizations and programmers have now delved into the vast field of Machine Learning. They often find themselves at an intersection of what can seem like two similar concepts: Generative AI and Reinforcement Learning.
While both technologies are discussed together, their primary focus is completely different. One is essentially an artist/writer who creates content digitally, while the other is a strategic/decision-making expert. The goal of this article is to give a detailed overview of the philosophy, application, and methodology of each technology so that you can better comprehend their role in today’s rapidly changing Tech Ecosystem.
Summary
“Explaining the Differences Between Generative AI and Reinforcement Learning ” shows how these two main approaches to Machine Learning work differently by comparing how they both create/optimization, train, and implement in the world.
Generative AI has been shown to be a means of creating content. Models are trained on massive amounts of data to learn statistical relationships within that data, so that when given an input, they can produce an output in some form of text, image, audio/video/code. The type of architecture used to make this possible is largely transformer-based, Generative Adversarial Networks (GANs), and diffusion models.
Reinforcement Learning (RL) is often seen as the process of optimizing decisions. An agent interacts with its environment, receiving either positive or negative reinforcement (reward or penalty). Through these interactions, the agent learns a policy that will maximize future reward. RL is typically represented as a Markov Decision Process (MDP), which uses Dynamic Programming to solve problems.
The article lists several differences that exist between these two types of machine learning. These include: creation vs. action; distribution learning vs. trial-and-error using an agent; offline generation vs. online control; and probabilistic vs. value-based planning. Additionally, the author discusses how the feedback loop differs between the two. Generative models do not require feedback during testing because they simply need to predict what was learned during training. In contrast, RL relies on having valid training environments and a well-designed reward function.
One example of a connection between the two is RLHF (reinforcement learning from human feedback). This involves converting human preferences about generated items into a reward function that allows the generative system to become more effective and safer.
Finally, the authors discuss several applications and provide guidelines on when to use each type of architecture.
The Core Concepts Defined
To understand the relationship between Generative AI and Reinforcement Learning, we have to start with definitions of each. While both are subfields of Machine Learning, they differ significantly in their approaches to solving problems.
What is Generative AI?
Generative AI is made up of Algorithms capable of generating original content — whether it be written text, image, video, audio, or code. So how do generative models create this new information? The process works by analyzing data patterns and, through the ingestion of large volumes of data, understanding relationships among the various elements, including statistical properties and structural aspects of the data.
Large Language Models (LLMs), for example, read billions of sentences to determine what follows a word naturally. As far as synthetic media goes, Deep Learning Architectures like GANs (Generative Adversarial Networks) and Diffusion Models are used to generate realistic-looking images and to duplicate human voices by mimicking complex visual and acoustic patterns.
How Generative AI Creates Content in Modern Systems
What is Reinforcement Learning?
On the flip side, reinforcement learning (RL) isn’t concerned with how you create content; it’s about what you do. Reinforcement learning is a behavioral form of machine learning. A computerized “agent,” a computer program designed to make decisions, will learn from the environment to make better choices.
The primary mechanism for developing this technology involves instructing autonomous agents through rewards and penalties. Agents are rewarded when they take an action that moves them closer to their objectives. They receive a penalty if they fail. Over time, the agent learns to optimize its cumulative reward. This illustrates the nature of goal-oriented learning – the overarching goal is to identify the optimal sequence of actions required to accomplish a particular task, e.g., a robot arm finding the best way to sort boxes or an AI finding the best way to play chess.
Machine Learning enables computers to learn from data and make predictions without explicit programming

Machine Learning is a fundamental area of Artificial Intelligence that allows computers to automatically learn from Data and produce Predictions.
Developers supply the computer with Examples – such as Images Labeled; Transaction Records; Streams of Sensor Readings – and allow Algorithms to discover Patterns that generalize to New Cases. There are many ways to approach this task, but some common ones include Supervised Learning (the Algorithm predicts a Known Target); Unsupervised Learning (the Algorithm discovers Structure in the Data without Labels); Semi-Supervised Learning (and Self-Supervised Learning), which both use Large Amounts of Raw Data.
The Typical Workflow associated with it includes collecting and cleaning the Data; Selecting Features or Representations; Choosing a Model (e.g., linear regression, decision trees, neural networks); and training the Model to Minimize Error on Historical Examples. Once the Model has been trained, it is validated, tested, and Monitored After Deployment to ensure it Remains Accurate as Real-World Conditions Change.
Because Quality of Data Drives Outcomes, it also entails Handling Bias, Preventing Overfitting, and Evaluating Performance using Metrics Such as Accuracy, Precision, Recall, Mean Squared Error.
In practice, teams use pipelines to facilitate version control of data, reproducible training, and A/B Testing to Compare Models Safely. They May Prefer Interpretable Models for Regulated Domains or Add Explainability Tools to Complex Networks. Ensuring Trustworthiness Under Changing Inputs and Stakeholder Understanding of Limits of Automation is Essential.
As We Speak Today, Machine Learning serves as the basis for Recommendation Systems, Fraud Detection, Forecasting, Medical Imaging, and Natural Language Applications. Additionally, this provides the Foundation for specialized areas of study, including Generative AI and Reinforcement Learning.
Generative AI differs from Reinforcement Learning in its Objectives and Feedback Signals. However, Both Forms of Learning Rely on Optimization and Representation Learning Principles Associated with Machine Learning.
Understanding Machine Learning Allows Teams to Decide When Classic Predictive Models are Sufficient and When Generative AI and Reinforcement Learning Can Provide More Adaptive and Creative Solutions.
Example
A city’s water supply system needs to determine which of its underground pipes are likely to fail during the coming month. The utility has collected ten years’ worth of information about each pipe segment: how old it is; what kind of material it is made from; what type of soil it is located in; at what pressures the pipe is being operated under; whether it has been repaired before; if there have been leaks in the pipe in recent times; and if there have been any building or construction activities occurring around the pipe.
An ML Model (a machine learning model using gradient-boosted trees), given all historical data, generates an estimated failure probability for each pipe segment. Then, the Utility uses those estimates to decide where to send inspection crews and replace pipes with higher-risk estimates. And because this process can be repeated every few months as additional repair work is completed and as additional readings come in from sensors attached to the existing pipe segments, the Utility can continue to improve its models, reduce emergency outages, and reduce repair costs over time.
Generative AI produces text, images, code, and other content by learning patterns from large datasets.

Generative AI can create text, images, code, and more. By studying large databases of existing items. In contrast to regular machine learning, which outputs a prediction or confidence level, generative AI models learn patterns in the number of combinations of sequences or pixel values, so they can produce their own outputs. Most modern Generative AI uses transformer networks to build language models and diffusion networks to build image models. These have been trained on large amounts of data to learn about word structure and grammar, styles, meanings, and the visual structures of images.
In practice, generative AI models can be used to automate email drafting, document summarizing, and translation; generate UI mock-ups; write unit test code; assist with idea generation; and generate synthetic data for development purposes. Additionally, these models can enable companies to prototype products quickly and at scale, as well as provide highly personalized experiences.
However, generative AI models can “hallucinate” plausible but incorrect statements, replicate biases in the data they have learned from, and potentially reveal sensitive information when data governance practices are poor. Therefore, most organizations use these models alongside methods such as retrieving information from trusted sources, engaging human reviewers, and placing “guardrails” around the types of unsafe or non-compliant responses the models may produce before deploying them in production environments.
Additionally, Generative AI and Reinforcement Learning are beginning to work together. Techniques such as RLHF (Reinforcement Learning from Human Feedback) allow developers to fine-tune their models to produce results that reflect users’ instructions and preferences. More generally, Generative AI and Reinforcement Learning can work together in Agented Systems: the generative component provides the agent with possible courses of action/plans, while the reinforcement learning component optimizes the agent’s behavior based upon rewards received in the environment.
For example, teams should clearly identify the intended use case(s) for adopting Generative AI and Reinforcement Learning technologies; evaluate quality based on relevant domain-specific criteria; and continuously assess performance trends. When appropriately controlled, Generative AI and Reinforcement Learning can augment each other – combining the ability to creatively generate new content with the capability to improve the generated content toward goals – while maintaining attention to accuracy, safety and accountability.
Example
The Game Studio has an enormous number of “Lore Snippets” (thousands) that need to be created for collectible items. Each snippet will have its own lore in terms of world rules and writing style. To assist writers, they create a Style Guide, a Canon Timeline, and a location Database (of all Locations), Faction Database (of all Factions), and a Character Constraint Database. They then use a generative AI tool to write very short item descriptions (item story & flavor text).
The generative AI ensures that the name of the item or object being written about matches the Canon. After creating these short item descriptions, an Editor reviews and approves them or makes corrections when inconsistencies are found. These corrections are used as additional examples to help train the Generative AI to produce better-quality content going forward. Ultimately, this process allows for faster creation of new content for their games while maintaining consistency across the lore. It also gives writers time to develop the Main Plot and Character Arcs in their games.
Reinforcement Learning: Reinforcement Learning trains AI systems through trial and error, helping them make smarter decisions over time.

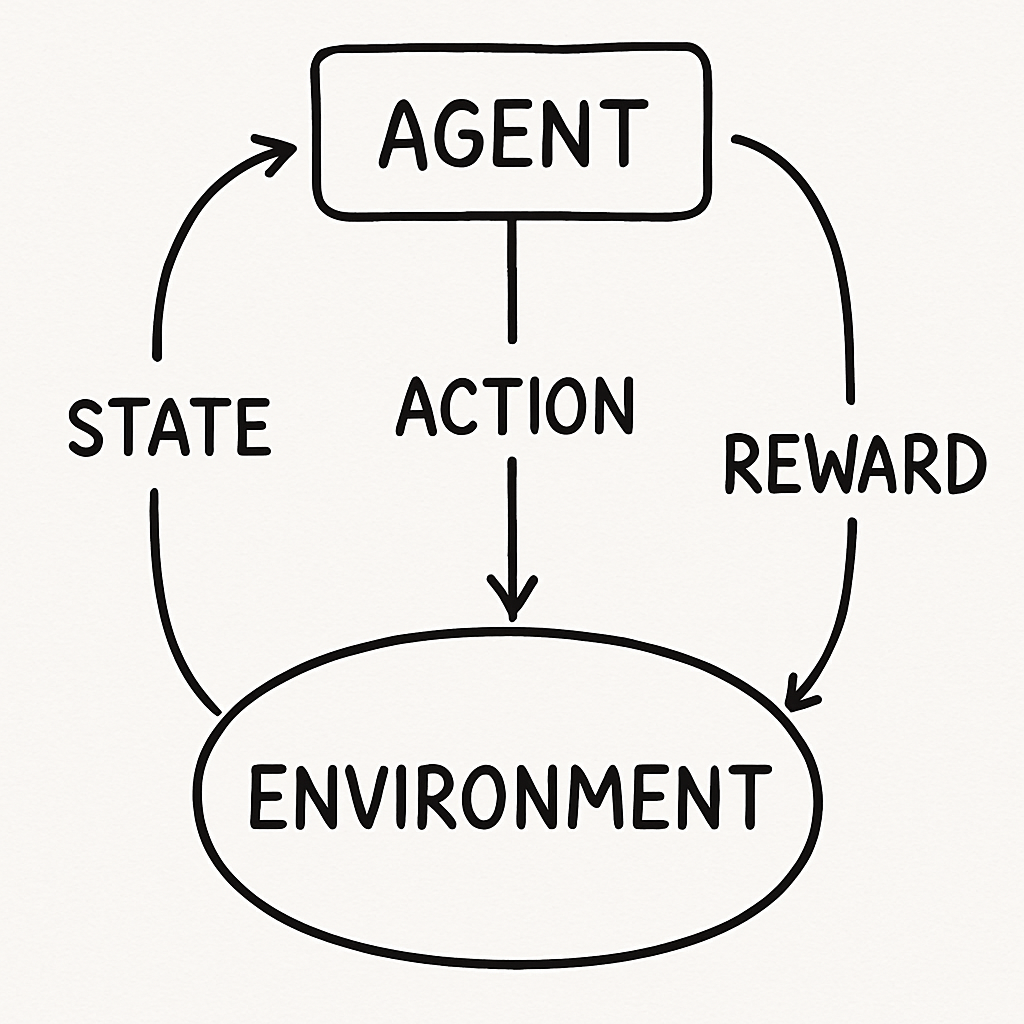
Reinforcement Learning is a type of machine learning training that uses trial and error to help develop better decision-making skills for artificial intelligence systems. Through interacting with environments, an “agent” takes an action based on what they observe, receives a reward or penalty from the outcome of that action, and attempts to find a “policy,” which represents the best course of action in every scenario, in order to maximize total long-term reward rather than just immediate reward. Therefore, Reinforcement Learning has proven successful in solving sequential decision-making problems that can compound over time.
The most common configuration for Reinforcement Learning consists of a state (the information available to the agent), an action (a choice made by the agent), and a reward signal (the criteria used to determine whether the agent’s performance was successful). Many algorithms exist today, including Q-learning and deep reinforcement learning methods that use neural networks to estimate the values of possible actions. These configurations enable Reinforcement Learning to be applied to very large and complex problems.
In practice, this will involve some degree of exploration (in which the agent attempts new actions) and exploitation (in which the agent selects the action currently believed to yield the highest reward). Exploration can be expensive or dangerous in real-world scenarios. As such, this can utilize many tools to minimize these risks. Examples of these tools include simulators, constrained policies, and offline data sets.
There are several areas of application for Reinforcement Learning. Some examples include robotics, optimizing inventory levels and prices, controlling traffic signals, playing games, and dynamically allocating resources within data centers. However, due to its nature, it can be difficult to stabilize during training, is highly dependent upon the quality of the reward function being optimized, and can lead to the development of undesirable behaviors in models if the rewards are not properly defined. As a result, evaluation should also include extensive testing, constraint identification, and continuous monitoring.
Today, we are seeing an increasing overlap between Generative AI and Reinforcement Learning. One area of intersection exists in planning in natural language, followed by adjusting decisions through feedback. Additionally, techniques such as RLHF demonstrate how Generative AI and Reinforcement Learning can be combined to ensure that models’ behavior aligns with human-identified preferences.
Teams developing these capabilities need a clear understanding of that to identify when trial-and-error optimization is required and to apply it responsibly with Generative AI and other Reinforcement Learning-based solutions in their production systems.
Example
Warehouse workers use small robots to transport items from storage shelves to a packing station. These robots move through very tight spaces (aisles) and often travel at speeds that can lead to collisions.
We have developed a Reinforcement Learning solution that trains individual robots to make decisions on how to navigate through this environment as quickly as possible. Each of these robots will be trained using a high-fidelity simulation: when they take an action (e.g., increase speed, turn left/right), they will receive a reward based on completing their delivery quickly; however, there may be additional negative rewards associated with taking certain actions such as nearly colliding with another robot, blocking access for other robots, or consuming excessive energy.
Once we train the robot’s decision-making process, we will implement it in our production system with all necessary safety constraints and real-time monitoring.
As the robots gain experience navigating the warehouse environment, they should help reduce congestion throughout the area, minimize processing times for selecting product (picking cycle time), and manage changes to the warehouse’s physical layout and/or changes in customer orders.
Generative AI and Reinforcement Learning: Generative AI creates content, while Reinforcement Learning improves decision-making through rewards and continuous learning

Generative AI and Reinforcement Learning have been described as creating rather than controlling; generating new content rather than optimizing action. Although both forms of AI are used to solve very different types of problems, they also have distinct feedback mechanisms and are therefore evaluated using different performance measures. With this understanding of both Generative AI and Reinforcement Learning, development teams will be able to determine which form of AI best fits their product’s objectives and limitations.
The primary focus of Generative AI is to learn patterns from large datasets, including text, images, audio, or code. These learned patterns are then used to create new content that looks and feels similar to the training dataset. Generative AI is primarily suited for tasks such as drafting, summarizing, translation, design, and prototyping. Evaluation criteria include output quality, coherency, usability, and safety. Often, these evaluation criteria are reviewed by humans or automated benchmarking tools. If your goal is to build a system capable of “creating” something on demand, Generative AI is almost always a more direct solution than Reinforcement Learning.
Reinforcement Learning is a type of machine learning that uses a training signal consisting of rewards given after each action taken by an agent. As the agent takes various actions and receives feedback, it learns a policy that maximizes the total reward over a given time horizon. An example application for Reinforcement Learning would be a robot arm attempting to pick up objects.
Rewards could be provided when the object was successfully picked up, and penalties could be assessed for failing to complete the task. Additionally, applications such as scheduling, pricing, navigation, and many other sequential decision-making tasks are well-suited to Reinforcement Learning. Metrics for measuring performance in Reinforcement Learning include reward collected per unit time, stability of the reward-collection process, sample efficiency of the learning process, and overall robustness of the final trained policy.
For applications requiring decision optimization under uncertainty, the preferred choice between Generative AI and Reinforcement Learning would clearly be Reinforcement Learning.
As more research is conducted into the integration of Generative AI and Reinforcement Learning, we are beginning to see these two areas of study being applied together. One common method of combining Generative AI and Reinforcement Learning is to have a generative model suggest possible plans or actions in natural language, while the reinforcement learning component uses rewards or human preferences to refine the system’s behavior. This is particularly useful in developing agentic systems and tool-based assistants. Alignment methods such as Reward Shaping via Human Feedback (RLHF) also utilize this combination of technologies.
In general terms, Generative AI and Reinforcement Learning operate differently in terms of objective (generating content vs. optimizing policies); training signal (likelihood of data vs. reward); and risk exposure during deployment (hallucination vs. reward hacking). Therefore, determining which technology best suits your needs begins with whether your primary need is to create content or improve decision-making over multiple iterations.
Example
Beginning with the customer service representative drafting a reply to assist the consumer as well as determining which is the most appropriate action for the support process (requesting additional information from the client, request the current status of an order, begin a return process, or refer the issue to a higher-level team member), this hybrid application will utilize a Generative AI to draft the written response and a reinforcement learning model to determine when to take each of the available actions in order to receive maximum rewards.
In a virtual test lab setting, the applications can explore many possible solutions and learn how quickly some problems can be resolved if only one important piece of information is requested before attempting to resolve them. By combining these two models of artificial intelligence, they have improved the tone and accuracy of responses, as well as the overall flow of conversations.
Generative AI vs Reinforcement Learning Comparison
| Feature | Generative AI | Reinforcement Learning |
|---|---|---|
| Primary Goal | Create New Content | Make optimal decisions |
| Training Method | Large datasets | Reward and penalty system |
| Output | Text, images, code, video | Actions and strategies |
| Feedback Type | Pattern recognition | Environmental rewards |
| Best Use Cases | Content generation | Robotics, gaming, automation |
| Example Models | GPT-4, Gemini, Claude | AlphaGo, OpenAI Five |
Source: Google DeepMind AlphaGo
Key Differences Between Creative AI and Decision-Making AI
A number of significant distinctions between generative (creative) AI and reinforcement learning (decision-making) become apparent when considering how each model is used differently relative to its original purpose.
1. The Core Objective: Creation vs. Action
Generative AI models were created primarily to imitate and/or generate using historical data. In contrast, Reinforcement Learning Models were originally developed to optimize or execute a strategy.
2. The Learning Paradigm
The difference in architecture between agent-based models and statistical distribution learning is obvious when comparing the two. As opposed to agent-based models, which utilize a single “agent” that continually adapts by making trial-and-error decisions within the defined bounds of a state space, generative models map statistical distributions. Thus, generative models determine the probability that generated samples resemble the original data.
3. Timing and Execution
In addition to differences in how each type of system utilizes its respective state spaces (as described above), there is also another key distinction between how reinforcement learning systems make real-time decisions versus how generative models create static outputs from previously collected data. Reinforcement learning systems are often used in situations with dynamically changing input parameters, such as self-driving cars and/or algorithmic trading platforms.
These systems produce output based upon the most recent information available at any given time and are expected to react accordingly. On the other hand, generative models cannot produce real-time responses to changing input parameters. Rather, they are designed to take in data prior to training and then to produce static output based upon the knowledge learned during that training process (e.g., an article or digital artwork).
4. Mathematical Foundations
The primary mathematical paradigms employed by each of these types of systems are fundamentally different. For example, one way to describe the differing paradigms is to discuss the distinct mathematical frameworks used by generative models vs. reinforcement learning models. Probabilistic frameworks vs. dynamic programming can be seen as a perfect illustration of this paradigmatic difference.
While generative models utilize complex probabilities to predict what will come after the last pixel in an image or what will come after the last word in a sentence, reinforcement learning models employ both dynamic programming and Markov decision processes to calculate the future benefit associated with a particular state and to enable agents to think multiple moves ahead.
How They Learn: Training and Feedback Loops
Understanding how a model’s feedback mechanism works is crucial for developers who want to create robust models. How a model receives feedback determines how well and how quickly it can learn.
Generative Models typically have a static feedback mechanism. Generative models are much older than reinforcement learning (RL) and were trained using either Self-Supervised Learning or Supervised Learning. A generative model predicts something based on the input and compares that prediction to the “ground truth” in the dataset used to train it. After comparing the two values, a measure of their distance is determined. This value is then used to adjust (update) the model’s internal weights to reduce the difference between predicted and actual output.
On the other hand, Reinforcement Learning is entirely driven by rewards. In RL, the feedback mechanism is dynamic. An RL Agent takes some type of action; as a result, the environment changes; a reward is generated and returned to the agent based on what happened after the action was taken; and, lastly, the agent uses the reward to update their policy. Because RL is a direct, experience-based approach, training environments significantly influence the model’s final performance.
For example, if you train a robot designed to walk through the use of a physics-based simulation that fails to take into account real-world gravity, friction, and other properties of reality, your model will completely fail when deployed in the real world. Therefore, simulations need to be very realistic.
Training and Feedback Example
| Scenario | Generative AI | Reinforcement Learning |
|---|---|---|
| Writing a Blog | Learns from millions of articles | Not suitable |
| Playing Chess | Learns game patterns | Learns through rewards and wins |
| Creating images | Generates from prompts | Not suitable |
| Robot Navigation | Limited | Learns optimal routes through trial and error |
| Warehouse Automation | Limited | Continuously improves actions |
Example:
A chatbot uses Generative AI to answer questions, while a warehouse robot uses Reinforcement Learning to optimize movement.
Source: NVIDIA Reinforcement Learning Guide
Bridging the Gap: When Two Worlds Collide
Generative AI has incredible potential for development, but it also has some significant shortcomings. GPTs, or generative pre-trained transformers, have several shortcomings, including a tendency to produce “false positives,” generate biased output, and/or output that doesn’t reflect user intent. As stated above, the primary issue is that they are simply trying to predict the next most likely word based on their training. They do not have an inherent sense of what constitutes “right vs. wrong” or “helpful vs. unhelpful.”
This is where reinforcement learning helps bridge the gap between these two disciplines by applying its decision-making capabilities to refine Generative AI’s creativity. To fully appreciate how reinforcement learning with human feedback creates such polite and effective chatbots as ChatGPT, we need to explore how it works. This is also referred to as RLHF. Below is a basic overview of how this process functions.
- Pre-training: A generative model is trained on vast amounts of text to learn language patterns.
- Human Feedback: Humans review the AI’s responses to various prompts and rank them based on helpfulness, accuracy, and safety.
- Reward Modeling: An RL reward model is trained on these human preferences.
- Optimization: The generative model is then put through a reinforcement learning loop. It practices generating answers, and the reward model gives it a high score for helpful answers and a low score for toxic or unhelpful ones.
Through RLHF, the AI learns to align its generative capabilities with human values, resulting in a significantly safer and more useful tool.
Real-World Applications: From Text to Physical Action
To truly appreciate both technologies, we must look at how they are deployed across different industries. The applications of AI in robotics vs creative writing perfectly encapsulate their respective strengths.
Generative AI Use Cases
- Content Marketing & Copywriting: LLMs can instantly draft blog posts, email campaigns, and ad copy, saving marketers hundreds of hours.
- Software Engineering: Generative models like GitHub Copilot assist developers by writing boilerplate code, finding bugs, and suggesting optimizations.
- Art and Design: Graphic designers use AI to prototype logos, generate background assets, and visualize architectural concepts in seconds.
- Customer Service: Advanced chatbots provide human-like interactions to resolve customer queries without human intervention.
Reinforcement Learning Use Cases
- Robotics and Manufacturing: RL trains robotic arms to assemble complex products, adapt to varying component sizes, and optimize movement for speed and safety.
- Autonomous Vehicles: Self-driving cars use RL to navigate traffic, decide when to brake, and adapt to unpredictable pedestrian behavior.
- Finance and Trading: Algorithmic trading bots are rewarded for maximizing portfolio returns while navigating volatile stock market environments.
Supply Chain Optimization: AI agents manage inventory levels and warehouse logistics by learning the most efficient routes and storage strategies over time.
Industry Adoption Statistics
| AI Technology | Business Adoption Rate |
|---|---|
| Generative AI | 65% of organizations regularly use GenAI |
| Machine Learning | 72% use predictive analytics |
| Automation AI | 55% use AI-driven automation |
| Conversational AI | 58% deploy AI chatbots |
| Reinforcement Learning | Growing in robotics and logistics |
Key Statistic:
- 65% of organizations report regularly using Generative AI in at least one business function.
Source: McKinsey State of AI Report

How to Choose the Right AI Architecture for a Project
For business leaders and data scientists, deciding which technology to implement can be daunting. Knowing how to choose the right AI architecture for a project ultimately comes down to clearly defining your end goal.
Here are a few actionable tips to help you decide:
- Define your output: If your project requires generating text, synthesizing voice, or creating images, Generative AI is your go-to architecture.
- Evaluate your environment: If your project requires navigating a complex, changing environment (like a video game, a physical warehouse, or a live stock market), you need Reinforcement Learning.
- Analyze your data availability: Generative models require massive datasets of existing examples to learn from. If you lack historical data but have a clear set of rules and a defined goal, RL enables an agent to generate its own data through simulation and trial and error.
- Consider hybrid models: Don’t be afraid to mix them. If you are building a conversational agent that needs to fetch real-time data and make strategic decisions while speaking naturally, utilizing a generative model fine-tuned with RLHF might be the perfect solution.
AI Project Selection Framework
| Project Goal | Recommended AI |
|---|---|
| Content Creation | Generative AI |
| Customer Support | Generative AI |
| Predictive Analytics | Machine Learning |
| Autonomous Driving | Reinforcement Learning |
| Robotics Control | Reinforcement Learning |
| Personalized Recommendations | Machine Learning + Reinforcement Learning |
| AI Agents | Hybrid Approach |
Example:
- Launching an AI content website → Generative AI
- Building a warehouse robot → Reinforcement Learning
- Creating a self-learning AI assistant → Hybrid AI
The Future of the AI Landscape
The advancements in artificial intelligence are occurring at such a pace that it’s inevitable there will be more overlap between what we consider ‘creation’ and what we consider ‘decision-making’.
While generative AI (vs) reinforcement learning represent two vastly different types of machine learning strategies, they are increasingly becoming less compartmentalized.
Generative AI has made significant advances in areas such as synthetic media and human-computer interaction, creating machines capable of communicating with humans in more expressive, imaginative ways. Meanwhile, reinforcement learning has been working behind the scenes to power all our autonomous systems, logistics networks, and dynamic algorithms that keep our modern world running.
to help companies take advantage of the rapidly evolving AI landscape by understanding how each type of AI works, trains, and optimizes, and which one is best suited to solve business challenges. Whether your goal is to write a novel, develop self-driving cars, or use both to build an intelligent, assistive personal assistant, selecting the right technology will enable you to start building the future.
Future AI Market Growth Statistics
| Segment | Expected Growth |
|---|---|
| Generative AI Market | CAGR above 35% through the decade |
| AI Software Market | Hundreds of billions in projected value |
| Robotics AI | Rapid growth across manufacturing |
| Autonomous Systems | Significant expansion expected |
| AI Agents | One of the fastest-growing AI categories |
Key Insight:
Experts expect future AI systems to combine Generative AI, Machine Learning, and Reinforcement Learning into autonomous agents capable of reasoning, planning, and execution.
Source: Grand View Research AI Market Report
Conclusion
Generative AI and reinforcement learning are two distinct yet equally effective approaches to creating smarter machines. Generative models use their understanding of the patterns and structure of the current data to generate new content (text, images, code, etc.) in accordance with these patterns.
Reinforcement Learning, on the other hand, uses rewards to learn what to do and trains agents through real-world interactions and long-term planning, improving their ability to make good decisions in dynamic environments.
In practice, there are many important distinctions between these two technologies; training signal, assessment techniques, risk of failure when deployed, and data requirements vary greatly. Therefore, which one is best suited to your goal depends on whether your goal is to create content that meets quality standards or to optimize behavior over time.
However, we see that this distinction between the two is becoming less pronounced. Methods like reinforcement learning from human feedback demonstrate how a decision-making framework can influence a generative system’s output toward usefulness, safety, and user intent. We are also seeing hybrid systems emerge. A hybrid system would have a generative component that produces possible plans of action/sequences and a reinforcement learning component that takes these sequences and iteratively optimizes them to produce the most successful results.
Ultimately, the key point is to first clearly define the problem you want to solve, then choose the type of machine learning architecture that aligns with the feedback you can reliably provide (either labeled examples for generating content or reward signals for sequential control). If used wisely, both architectures can help accelerate innovation while keeping your eye on performance, reliability, and governance.
FAQs
- What is the main difference between Generative AI and Reinforcement Learning?
Generative AI creates new content (text, images, code) by learning patterns from data, while Reinforcement Learning (RL) learns optimal decisions by interacting with an environment and maximizing rewards over time. - When should I choose Generative AI for a project?
Use Generative AI when your primary output is content—drafting, summarizing, translating, generating designs, or producing code—where success is judged by quality, coherence, and usefulness. - When is Reinforcement Learning the better fit?
Choose RL when the problem is sequential decision-making—robot control, routing, scheduling, trading, or resource allocation—where actions affect future states, and you can define a reward signal. - How does RLHF relate to both approaches?
Reinforcement Learning from Human Feedback (RLHF) uses human preference rankings to build a reward model, then applies RL-style optimization to fine-tune a generative model so it better follows instructions and avoids unsafe outputs. - Can Generative AI and Reinforcement Learning be combined in one system?
Yes. A generative model can propose plans or actions (often in natural language), and an RL component can optimize them using rewards or feedback – a capability useful for tool-using assistants, autonomous agents, and alignment workflows.
Garikapati Bullivenkaiah is a seasoned entrepreneur with a rich multidisciplinary academic foundation—including LL.B., LL.M., M.A., and M.B.A. degrees—that uniquely blend legal insight, managerial acumen, and sociocultural understanding. Driven by vision and integrity, he leads his own enterprise with a strategic mindset informed by rigorous legal training and advanced business education. His strong analytical skills, honed through legal and management disciplines, empower him to navigate complex challenges, mitigate risks, and foster growth in diverse sectors. Committed to delivering value, Garikapati’s entrepreneurial journey is characterized by innovative approaches, ethical leadership, and the ability to convert cross-domain knowledge into practical, client-focused solutions.














{kind=link}